
Help & Knowledge Base
Customizing Result File Names
Special keywords can be used as placeholders in the output file names, to be replaced with dynamic values during the execution.
A trivial example is prefixing each document with the page number, when splitting.
[CURRENTPAGE]
A reference to the current page number in the input document.
Example: [CURRENTPAGE###] will generate filesnames like 001.pdf, 002.pdf.
Example: [CURRENTPAGE##] generates 01.pdf, 02.pdf, etc.
[TIMESTAMP]
Ensures unique output filenames, being replaced with current date & time.
[FILENUMBER]
Ensures unique output filenames, replaced with a file number according to the output order.
Example: [FILENUMBER###] generates 001, 002
Example: [FILENUMBER13] starts with the counter at 13, generating 13, 14,
etc.
[BASENAME]
Does not ensure unique output filenames, and it must be used together with other placeholders ensuring unique names. It is replaced with original name of the input document, without the extension.
Example: [CURRENTPAGE]_[BASENAME] would generate 1_input-file.pdf, 3_input-file.pdf,
etc.
[BOOKMARK_NAME]
This pattern is replaced by current bookmark's name. Only applicable in the "Split by bookmarks" tool.
[BOOKMARK_NAME_STRICT]
Same behavior as [BOOKMARK_NAME] with the difference that non-alphanumberic characters are
removed.
Example: [CURRENTPAGE]-[BOOKMARK_NAME] would generate 1-Introduction.pdf, 4-Chapter
1.pdf, etc.
[TEXT]
This pattern is applicable only in the "Split by text" tool. It is replaced with the text found in the page area selected.
Example: [CURRENTPAGE]-[TEXT] would generate 1-Invoice 3456789.pdf, 4-Invoice
234567.pdf, etc.
[TEXT1], [TEXT2], etc.
This pattern is applicable only in the "Rename" tool. It is replaced with the text found in the selected area.
Example: [TEXT2]-[TEXT1] would generate John Doe-Invoice 3456789.pdf, Jane Doe-Invoice
234567.pdf, etc.
Sejda Desktop Enterprise Install
To deploy Sejda Desktop in an enterprise environment using a pre-configured volume license key use this command:
msiexec /i sejda-desktop_x.y.z_x64.msi LICENSE_KEY="1234-ABCD-1234-ABCD"
Any options provided will be configured machine-wide and will apply for all users on the system.
| LICENSE_KEY | License key | LICENSE_KEY="1234-ABCD-1234-ABCD" |
| LOCALE | UI language | en, es, de, fr,it or pt |
| UPDATE_CHECK | Disables checking for new versions | UPDATE_CHECK="false" |
| DISABLED_FEATURES | List of features to be disabled | DISABLED_FEATURES="edit.whiteout" |
| EULA_ACCEPTED | Accept EULA and no longer prompt on first use | EULA_ACCEPTED="true" |
| AUTO_REPORT_ERRORS | Configure automated error reporting and no longer prompt on first use | AUTO_REPORT_ERRORS="false" |
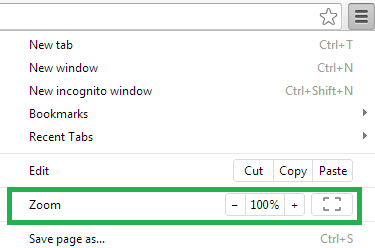
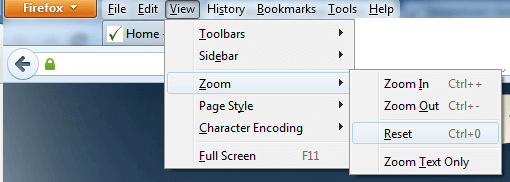
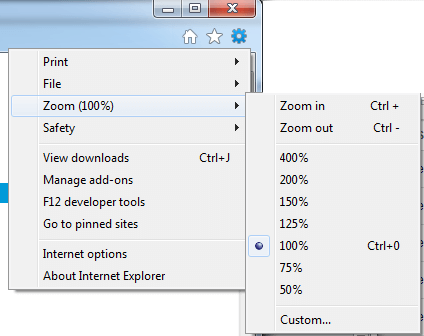
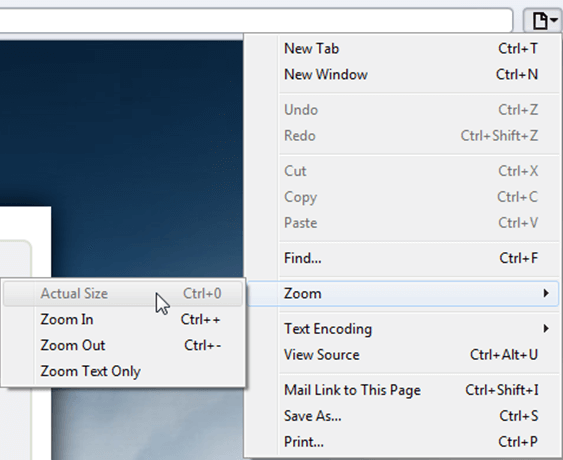
Resetting Browser Zoom
Choosing a zoom level of anything other than 100% (the default) can cause problems in pages where we render PDF pages.
If you are warned about it, reset the browser zoom to 100%.
The quickest way to return your browser to this zoom setting is to use the keyboard shortcut Ctrl + 0 on Windows or Cmd + 0 on Mac.
Additional browser-specific instructions for changing the zoom level are detailed below.
Chrome
Firefox
Internet Explorer
Safari
Sejda Desktop - Loading local fonts failed
Sejda Desktop fails to load the fonts installed on your system?
Windows 7: Please install "Platform update for Windows 7 SP1": https://support.microsoft.com/en-us/kb/2670838.
Linux: Please install libfontconfig-dev: sudo apt-get install libfontconfig-dev
Sejda Desktop - Add your fonts
Sejda Desktop can use your custom fonts when editing PDF documents.
1) Install the font on your system. See help for Windows or Mac.
2) Open Sejda Desktop, then open a PDF document with the Editor.
3) Type text on the page. From the context menu select "Fonts > More fonts".
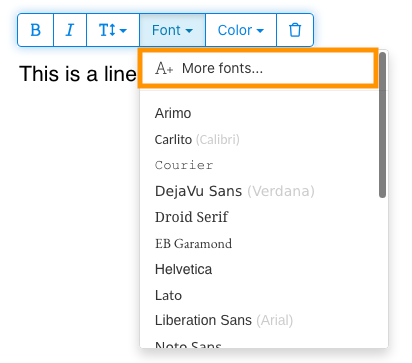
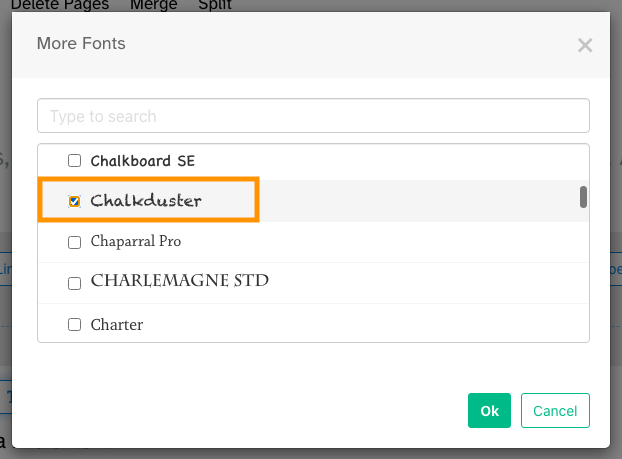
4) Select the font you would like to use and click "OK".
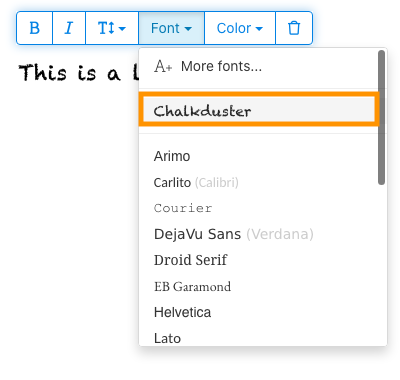
5) Click on the newly added font to use it for your text.
How long does it take for a refund to be processed?
It can take anywhere from 5-10 business days for a refund to show up on your bank account.
In some cases, the refund might be processed as a reversal, meaning the original payment will disappear from the account statement entirely and the balance will reflect as though the charge never occurred.
If you do not see the refund after 10 business days and you are still seeing the original charge on your bank statement, please reach out to support for more information.
How can you delete your FastSpring data?
If you've placed an order through FastSpring, our online authorized reseller & merchant of record, you can send your data erasure request to privacy@fastspring.com.
Malwarebytes interfering with Sejda Desktop?
Do you have Malwarebytes installed?
Please try temporarily turning Malwarebytes off and see if that solves the problem: Instructions here
You can report this problem with Malwarebytes: Report false positive
Could not convert: Page uses CAPTCHAs
The website you are trying to convert uses CAPTCHAs to block automated robots (such as our converter) from visiting their website.
There is no work around this.
See if the browser extension helps with your use-case:
HTML to PDF browser-extension
Install Linux OCR engine
Sejda Desktop does not ship with an embedded OCR engine on Linux, it uses the one available on the system.
To install an OCR engine, please run the following command:
sudo apt-get install -y tesseract-ocr tesseract-ocr-all
Once the command completes, return to Sejda Desktop and run your OCR task again.
Install Linux OCR language data
The OCR engine is installed successfully, but it is missing language data.
To install language data, please run the following command:
sudo apt-get install -y tesseract-ocr-all
About 667M of data will be downloaded and installed.
Once the command completes, return to Sejda Desktop and run your OCR task again.
Ik word gevraagd om het eigenaarswachtwoord in te voeren
Waarom wordt er om een wachtwoord gevraagd?
Sommige PDF-documenten hebben beveiligingsinstellingen die bepaalde acties beperken, zoals printen, tekst kopiëren, bewerken of annotaties toevoegen. Deze beperkingen zijn ingesteld door de maker van het document om te bepalen hoe de inhoud wordt gebruikt en gedeeld.
Als we detecteren dat een PDF deze beperkingen heeft, vragen we je om het eigenaarswachtwoord. Het invoeren van dit wachtwoord ontgrendelt het document en geeft volledige toegang tot alle functies en machtigingen. Deze stap zorgt ervoor dat alleen bevoegde personen de beperkingen van de oorspronkelijke auteur kunnen wijzigen of verwijderen.
Wat is een eigenaarswachtwoord?
Een eigenaarswachtwoord wordt ingesteld door de maker van de PDF om onbevoegde wijzigingen aan het document te voorkomen. Het verschilt van een gebruikerswachtwoord, dat het openen van het document volledig beperkt. Als je het eigenaarswachtwoord hebt, betekent dit dat je volledige rechten hebt voor het document.
Wat als ik het eigenaarswachtwoord niet heb?
Als je het eigenaarswachtwoord niet hebt, blijf je beperkte toegang houden op basis van de beperkingen in de PDF.
Om volledige toegang te krijgen, moet je een ontgrendelde versie van het document verkrijgen.
Hoe voorkom ik dat ik telkens het eigenaarswachtwoord moet typen?
Je kunt een PDF unlocker tool gebruiken om de beperkingen uit je document te verwijderen. Dit doe je maar één keer. Daarna wordt er niet meer om het eigenaarswachtwoord voor het document gevraagd.
Open het PDF-document in Google Chrome, druk op Ctrl+P om te printen, kies bij "Bestemming" voor "Opslaan als PDF" rechtsboven en klik op "Opslaan".
Lost een betaald abonnement het probleem op?
Nee, er wordt nog steeds om het eigenaarswachtwoord gevraagd, ook als je een betaald abonnement bij ons hebt.
Kunnen jullie mij het eigenaarswachtwoord vertellen?
Nee, wij weten het eigenaarswachtwoord van je documenten niet. Het eigenaarswachtwoord is gekozen door de persoon die het document heeft gemaakt en is anders dan je inlogwachtwoord.
Ik kan een gescand document niet bewerken of converteren
Waarom kunnen gescande documenten niet bewerkt of geconverteerd worden?
Wanneer je een fysiek document scant om een PDF te maken, maakt de scanner een afbeelding van elke pagina. Dit proces zet de tekst, afbeeldingen en opmaak om in één afbeeldingsbestand dat in de PDF is opgesloten. In tegenstelling tot standaard PDF's, waarbij tekst wordt opgeslagen als losse tekens en regels, zien gescande PDF's elke pagina als één grote afbeelding.
Omdat de tekst in een gescande PDF deel uitmaakt van een afbeelding, kunnen PDF-editors deze niet direct herkennen of wijzigen. De software ziet alleen een verzameling pixels, geen herkenbare letters of woorden. Hierdoor is het onmogelijk om tekstparagrafen te bewerken of wijzigingen aan te brengen zoals in een gewoon tekst-gebaseerd PDF-document.
Hoe bepaal je of een document een scan is?
Een manier om te bepalen of een PDF een gescande afbeelding is, is door deze te openen met een PDF-viewer en te proberen de tekst met je muis te selecteren. In een bewerkbare PDF kun je tekst markeren door er met je cursor overheen te klikken en te slepen. Als je geen tekst kunt selecteren en de hele pagina zich als één afbeelding gedraagt, is het waarschijnlijk een gescand document.
Opmerking: Sommige gescande documenten worden verwerkt met Optical Character Recognition (OCR) om "doorzoekbare" scans te worden, waarbij tekst wel geselecteerd en doorzocht kan worden. Deze documenten blijven echter scans en kunnen niet worden bewerkt of geconverteerd zoals standaard PDF's.
Ik weet zeker dat mijn document geen scan is
Sommige documenten lijken op scans omdat hun inhoud als afbeeldingen op elke pagina is ingebed. Dit kan gebeuren bij documenten gemaakt van screenshots of wanneer tekst is omgezet naar contouren in plaats van bewerkbare tekst.
Hoewel dit technisch gezien geen scans zijn, werken ze op een vergelijkbare manier. Helaas ondersteunen we het bewerken of converteren van dit soort documenten ook niet.
Lost een betaald abonnement het probleem op?
Nee, een upgrade naar een betaald abonnement maakt het niet mogelijk om gescande documenten te bewerken of te converteren. Het bewerken of converteren van scans wordt niet ondersteund, ongeacht je abonnement.
Ik weet zeker dat ik dit document eerder kon bewerken
We hebben nooit ondersteuning geboden voor het bewerken of converteren van gescande documenten. Als je het document eerder wel kon bewerken, is het waarschijnlijk anders naar PDF geëxporteerd dan het huidige document.
Sejda Desktop faalt vanwege machtigingen
Er zijn 2 veelvoorkomende oorzaken voor deze fout: onvoldoende machtigingen of interferentie door antivirussoftware.
Onvoldoende rechten: Mogelijk moet je Sejda Desktop uitvoeren als administrator. Rechtermuisklik op de app en kies "Meer" > "Als administrator uitvoeren".
Antivirus of beveiligingssoftware: Schakel je antivirus tijdelijk uit om te zien of dat het probleem oplost.
Sejda Desktop installeren op Chromebook
Sejda Desktop kan op een Chromebook worden geïnstalleerd via de Linux-ontwikkelomgeving (ook bekend als Crostini).
Vereisten
De Linux-ontwikkelomgeving moet ingeschakeld zijn op je Chromebook. Ga om dit in te schakelen naar Instellingen → Geavanceerd → Ontwikkelaars → Linux-ontwikkelomgeving en volg de stappen.
Niet alle Chromebooks ondersteunen Linux. Oudere of goedkopere modellen hebben deze optie mogelijk niet.
1. Download de Linux-versie (.deb)
2. Installeren in Terminal
Open de Linux Terminal-app en voer uit:
cd ~/Downloads sudo dpkg -i sejda-desktop_*.deb sudo apt -f install
3. Starten
sejda-desktop
Of start het vanuit de map met Linux-apps in je ChromeOS-launcher.
Problemen oplossen: app opent niet
Als Sejda Desktop niet verschijnt of geen venster opent, installeer dan de ontbrekende GUI-bibliotheken:
sudo apt install -y libgconf-2-4 libatk1.0-0 libatk-bridge2.0-0
OCR-functies
Sejda Desktop op Linux gebruikt de OCR-engine van het systeem.
Zie Linux OCR-engine installeren voor instructies