
Help & Knowledge Base
Customizing Result File Names
Special keywords can be used as placeholders in the output file names, to be replaced with dynamic values during the execution.
A trivial example is prefixing each document with the page number, when splitting.
[CURRENTPAGE]
A reference to the current page number in the input document.
Example: [CURRENTPAGE###] will generate filesnames like 001.pdf, 002.pdf.
Example: [CURRENTPAGE##] generates 01.pdf, 02.pdf, etc.
[TIMESTAMP]
Ensures unique output filenames, being replaced with current date & time.
[FILENUMBER]
Ensures unique output filenames, replaced with a file number according to the output order.
Example: [FILENUMBER###] generates 001, 002
Example: [FILENUMBER13] starts with the counter at 13, generating 13, 14,
etc.
[BASENAME]
Does not ensure unique output filenames, and it must be used together with other placeholders ensuring unique names. It is replaced with original name of the input document, without the extension.
Example: [CURRENTPAGE]_[BASENAME] would generate 1_input-file.pdf, 3_input-file.pdf,
etc.
[BOOKMARK_NAME]
This pattern is replaced by current bookmark's name. Only applicable in the "Split by bookmarks" tool.
[BOOKMARK_NAME_STRICT]
Same behavior as [BOOKMARK_NAME] with the difference that non-alphanumberic characters are
removed.
Example: [CURRENTPAGE]-[BOOKMARK_NAME] would generate 1-Introduction.pdf, 4-Chapter
1.pdf, etc.
[TEXT]
This pattern is applicable only in the "Split by text" tool. It is replaced with the text found in the page area selected.
Example: [CURRENTPAGE]-[TEXT] would generate 1-Invoice 3456789.pdf, 4-Invoice
234567.pdf, etc.
[TEXT1], [TEXT2], etc.
This pattern is applicable only in the "Rename" tool. It is replaced with the text found in the selected area.
Example: [TEXT2]-[TEXT1] would generate John Doe-Invoice 3456789.pdf, Jane Doe-Invoice
234567.pdf, etc.
Sejda Desktop Enterprise Install
To deploy Sejda Desktop in an enterprise environment using a pre-configured volume license key use this command:
msiexec /i sejda-desktop_x.y.z_x64.msi LICENSE_KEY="1234-ABCD-1234-ABCD"
Any options provided will be configured machine-wide and will apply for all users on the system.
| LICENSE_KEY | License key | LICENSE_KEY="1234-ABCD-1234-ABCD" |
| LOCALE | UI language | en, es, de, fr,it or pt |
| UPDATE_CHECK | Disables checking for new versions | UPDATE_CHECK="false" |
| DISABLED_FEATURES | List of features to be disabled | DISABLED_FEATURES="edit.whiteout" |
| EULA_ACCEPTED | Accept EULA and no longer prompt on first use | EULA_ACCEPTED="true" |
| AUTO_REPORT_ERRORS | Configure automated error reporting and no longer prompt on first use | AUTO_REPORT_ERRORS="false" |
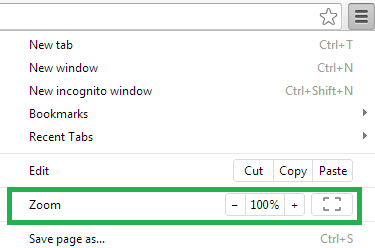
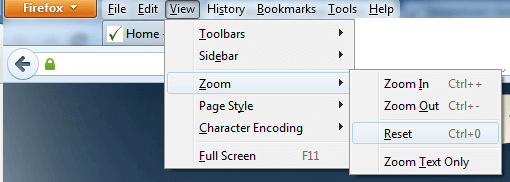
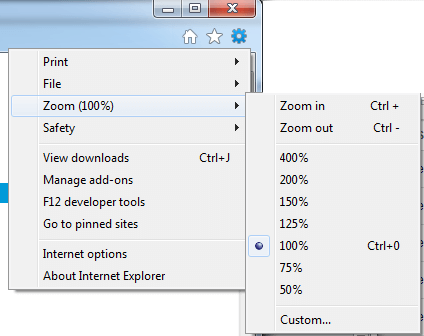
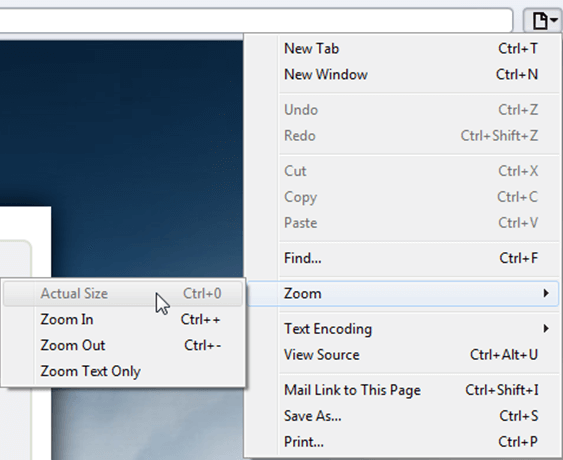
Resetting Browser Zoom
Choosing a zoom level of anything other than 100% (the default) can cause problems in pages where we render PDF pages.
If you are warned about it, reset the browser zoom to 100%.
The quickest way to return your browser to this zoom setting is to use the keyboard shortcut Ctrl + 0 on Windows or Cmd + 0 on Mac.
Additional browser-specific instructions for changing the zoom level are detailed below.
Chrome
Firefox
Internet Explorer
Safari
Sejda Desktop - Loading local fonts failed
Sejda Desktop fails to load the fonts installed on your system?
Windows 7: Please install "Platform update for Windows 7 SP1": https://support.microsoft.com/en-us/kb/2670838.
Linux: Please install libfontconfig-dev: sudo apt-get install libfontconfig-dev
Sejda Desktop - Add your fonts
Sejda Desktop can use your custom fonts when editing PDF documents.
1) Install the font on your system. See help for Windows or Mac.
2) Open Sejda Desktop, then open a PDF document with the Editor.
3) Type text on the page. From the context menu select "Fonts > More fonts".
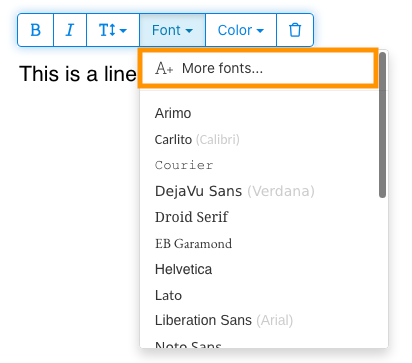
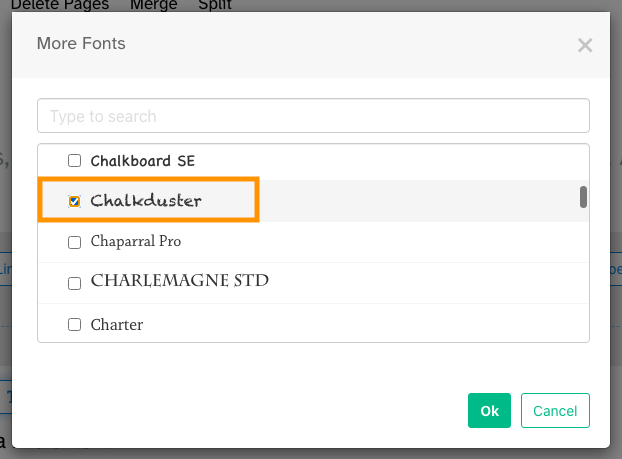
4) Select the font you would like to use and click "OK".
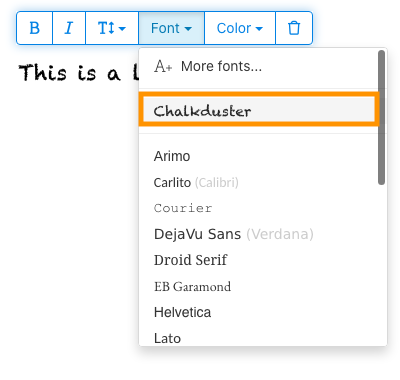
5) Click on the newly added font to use it for your text.
How long does it take for a refund to be processed?
It can take anywhere from 5-10 business days for a refund to show up on your bank account.
In some cases, the refund might be processed as a reversal, meaning the original payment will disappear from the account statement entirely and the balance will reflect as though the charge never occurred.
If you do not see the refund after 10 business days and you are still seeing the original charge on your bank statement, please reach out to support for more information.
How can you delete your FastSpring data?
If you've placed an order through FastSpring, our online authorized reseller & merchant of record, you can send your data erasure request to privacy@fastspring.com.
Malwarebytes interfering with Sejda Desktop?
Do you have Malwarebytes installed?
Please try temporarily turning Malwarebytes off and see if that solves the problem: Instructions here
You can report this problem with Malwarebytes: Report false positive
Could not convert: Page uses CAPTCHAs
The website you are trying to convert uses CAPTCHAs to block automated robots (such as our converter) from visiting their website.
There is no work around this.
See if the browser extension helps with your use-case:
HTML to PDF browser-extension
Install Linux OCR engine
Sejda Desktop does not ship with an embedded OCR engine on Linux, it uses the one available on the system.
To install an OCR engine, please run the following command:
sudo apt-get install -y tesseract-ocr tesseract-ocr-all
Once the command completes, return to Sejda Desktop and run your OCR task again.
Install Linux OCR language data
The OCR engine is installed successfully, but it is missing language data.
To install language data, please run the following command:
sudo apt-get install -y tesseract-ocr-all
About 667M of data will be downloaded and installed.
Once the command completes, return to Sejda Desktop and run your OCR task again.
Jag blir ombedd att ange ägarlösenordet
Varför blir jag tillfrågad om ett lösenord?
Vissa PDF-dokument har säkerhetsinställningar som begränsar vissa åtgärder, som att skriva ut, kopiera text, redigera eller lägga till anteckningar. Dessa begränsningar läggs till av dokumentets skapare för att styra hur innehållet används och delas.
När vi upptäcker att en PDF har dessa begränsningar frågar vi efter ägarlösenordet. Genom att ange det här lösenordet låses dokumentet upp och ger full åtkomst till alla funktioner och behörigheter. Det här steget säkerställer att endast behöriga personer kan ändra eller ta bort de begränsningar som skaparen har ställt in.
Vad är ett ägarlösenord?
Ett ägarlösenord ställs in av PDF-skaparen för att förhindra obehöriga ändringar i dokumentet. Det skiljer sig från ett användarlösenord, som begränsar möjligheten att öppna dokumentet helt och hållet. Om du har ägarlösenordet betyder det att du har full behörighet till dokumentet.
Vad händer om jag inte har ägarlösenordet?
Om du inte har ägarlösenordet kommer du fortsätta ha begränsad åtkomst baserat på de begränsningar som finns i PDF-filen.
För att få full åtkomst behöver du skaffa en upplåst version av dokumentet.
Hur kan jag slippa skriva in ägarlösenordet varje gång?
Du kan använda ett PDF-upplåsningsverktyg för att ta bort behörighetsbegränsningarna från ditt dokument. Du gör det bara en gång. Då kommer du inte att bli tillfrågad om ägarlösenordet för det dokumentet mer.
Öppna PDF-dokumentet i Google Chrome, tryck Ctrl+P för att skriva ut, välj "Spara som PDF" som "Destination" uppe till höger och klicka sedan på "Spara".
Kommer ett betalabonnemang lösa problemet?
Nej, du kommer fortfarande att bli tillfrågad om ägarlösenordet även om du har ett betalabonnemang hos oss.
Kan ni berätta ägarlösenordet för mig?
Nej, vi vet inte ägarlösenordet för dina dokument. Ägarlösenordet valdes av personen som skapade ditt dokument och det är inte samma som ditt inloggningslösenord.
Jag kan inte redigera eller konvertera ett skannat dokument
Varför kan skannade dokument inte redigeras eller konverteras?
När du skannar ett fysiskt dokument för att skapa en PDF fångar skannern en bild av varje sida. Denna process gör om text, grafik och layout till en enda bildfil som bäddas in i PDF-filen. Till skillnad från vanliga PDF-filer, där text lagras som enskilda tecken och rader som kan markeras, kopieras och redigeras, behandlar skannade PDF-filer varje sida som en enda stor bild.
Eftersom texten i en skannad PDF är en del av en bild kan PDF-redigerare inte känna igen eller ändra den direkt. Programvaran ser bara en samling pixlar, inte urskiljbara bokstäver eller ord. Detta gör det omöjligt att redigera textstycken eller göra ändringar som du skulle i ett vanligt, textbaserat PDF-dokument.
Hur avgör man om ett dokument är en skanning?
Ett sätt att avgöra om en PDF är en skannad bild är att öppna den i en PDF-visare och försöka markera texten med musen. I en redigerbar PDF kan du markera text genom att klicka och dra markören över den. Om du inte kan markera text och hela sidan fungerar som en enda bild, är det förmodligen ett skannat dokument.
Obs: Vissa skannade dokument bearbetas med Optical Character Recognition (OCR) för att bli "sökbara" skanningar, där text kan markeras och sökas i. Men dessa dokument är fortfarande skanningar och kan inte redigeras eller konverteras som vanliga PDF-filer.
Jag är säker på att mitt dokument inte är en skanning
Vissa dokument liknar skanningar eftersom innehållet är inbäddat som bilder på varje sida. Detta kan hända med dokument skapade från skärmdumpar eller när text har konverterats till konturer istället för att vara inbäddad som redigerbar text.
Även om dessa inte tekniskt sett är skanningar, fungerar de på ett liknande sätt. Tyvärr stödjer vi inte heller redigering eller konvertering av dessa typer av dokument.
Kommer ett betalabonnemang lösa problemet?
Nej, att uppgradera till ett betalt abonnemang gör det inte möjligt att redigera eller konvertera skannade dokument. Redigering eller konvertering av skanningar stöds inte, oavsett din prenumerationsnivå.
Jag är säker på att jag kunde redigera detta dokument tidigare
Vi har aldrig haft stöd för att redigera eller konvertera skannade dokument. Om du kunde redigera dokumentet tidigare beror det troligen på att det exporterades till PDF på ett annat sätt än det nuvarande dokumentet.
Sejda Desktop misslyckas på grund av behörigheter
Det finns 2 vanliga orsaker till det här felet: otillräckliga behörigheter eller störningar från antivirusprogram.
Otillräckliga behörigheter: Du kan behöva köra Sejda Desktop med administratörsbehörighet. Högerklicka på appen och välj sedan "Mer" > "Kör som administratör".
Antivirus- eller säkerhetsprogram: Testa att tillfälligt inaktivera ditt antivirusprogram för att se om det löser problemet.
Installera Sejda Desktop på Chromebook
Sejda Desktop kan installeras på en Chromebook med hjälp av Linux-utvecklingsmiljön (även känd som Crostini).
Krav
Din Chromebook måste ha Linux-utvecklingsmiljön aktiverad. För att aktivera den, gå till Settings → Advanced → Developers → Linux development environment och följ installationsstegen.
Alla Chromebooks stöder inte Linux. Äldre modeller eller budgetmodeller kanske inte har det här alternativet tillgängligt.
1. Ladda ner Linux-versionen (.deb)
2. Installera den i Terminal
Öppna appen Linux Terminal och kör:
cd ~/Downloads sudo dpkg -i sejda-desktop_*.deb sudo apt -f install
3. Kör den
sejda-desktop
Eller starta den från mappen Linux-appar i din ChromeOS-launcher.
Felsökning: appen öppnas inte
Om Sejda Desktop inte visas eller om ett fönster inte öppnas, installera de GUI-bibliotek som saknas:
sudo apt install -y libgconf-2-4 libatk1.0-0 libatk-bridge2.0-0
OCR-funktioner
Sejda Desktop på Linux använder systemets OCR-motor.
Se Installera Linux OCR-motor för instruktioner